ラボラトリーズ
スパースモデリングの深化と高次元データ駆動科学の創成 -数理的メタファーの重要性-
2017年09月26日
岡田真人
おかだまさと
東京大学 大学院 新領域創成科学研究科
ここでは新学術領域研究「スパースモデリングの深化と高次元データ駆動科学の創成」を私の研究上の個人的な経験にもとづき紹介する.産官学において人工知能の研究が注目されている.科学史的視点にたてば,この人工知能の研究の隆盛の一因はニューラルネットワークの再評価であり,現在は第 3 次ニューロブームと解釈することもできる.私は,その一世代前,25 〜 30 年前の第 2 次ニューロブームの際に,研究者としての道を歩き出した.第 2 次ニューロブームが起きた理由は,幾つかの魅力的な研究成果にもとづくパラダイムが同時に提案されたからだと考えられる.その一つは,連想記憶モデルと呼ばれる脳科学の記憶のモデルの,Hopfield による再提案と,連想記憶モデルと物理学の磁石のモデルとの数理科学的な対応の指摘である[1].
数理的メタファーとデータ駆動科学
磁石の構成要素のスピンは上向きの状態と下向きの状態に対応する±1の二状態で表現される.連想記憶モデルでは,神経細胞を±1の出力をもつ素子で表現する.複雑な神経細胞の挙動を近似することで,記憶のモデルを磁石の統計力学を使って解析できる.モデルの単純さが発想を加速し,いくつまで記憶が憶えられるか,また,記憶の距離関係に階層構造を持たせると何が起こるかなど,モデルに関する数理的な知見が増加する.これが数理科学の醍醐味の一つであろう.私は似た記憶パターンがクラスター状に分布するモデルについての記憶想起の過程を研究していた.このモデルでは,図1(a)のように,似ている記憶パターン(ξ1, ξ2, ξ3)の中心の混合状態(η)が平衡状態になる.この現象をAmariは概念形成と呼んだ[2].これは沢山のイヌを憶えると,一般的なイヌの概念が脳の中に自動的に形成されるという仮説である.現に私は,図1(b)のように,個別の記憶が想起される途中で,系の状態が一旦,概念に近づくという計算結果を得た[3, 4].図1(b)の×が力学系の不安定平衡点であり,図1(b)の点線が矢印のような,安定多様体と不安定多様体を持つことに起因している.この系では安定多様体に対応する成分が急速に減弱し,そのあと不安定多様体にそって,系は移動する.
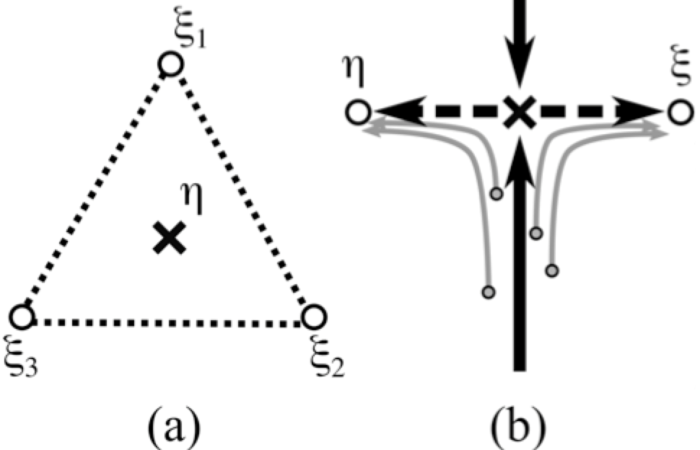
この数理的な知見を,実際の脳の実験と比較するのはそれほど簡単ではない.例えば,物理学等のモデルは,実験結果を定量的に予測する.その場合は,物理モデルと実験の比較は,モデルと実験からでる結果を直接比較すればよい.一方,連想記憶モデルでは神経細胞の挙動を単純化したために,実験で得られる神経細胞の挙動と定量的に比較することはできない.このような視点で,神経回路モデルはモデルというよりは,数理的メタファーであるという立場に立つことが自然である.定量的予言能力は持たないが,定性的な本質であると言っても良い.数理的なメタファーから得られた定性的事実を,定量的な計測結果とどのように対応づけるか.これは,それほど簡単ではない.物理学等のモデルのだす定量的な予測を,定量的な計測結果と対応づける論理を直接適用することはできない.
そこで私達が用いた方法は,Sugaseらの実験データに対して主成分分析やクラスタリングなどの統計学や機械学習を適用して,神経活動の高次元空間に埋め込まれた記憶状態の性質を取り扱うことであった[5, 6].その結果,大脳皮質の高次視覚野の神経細胞集団が,図1(b)でしめすような挙動をすることがわかった.
数理的メタファーは,脳科学だけではなく,量子力学などの第一原理からの演繹が難しい,生物学や地学等のいわゆる理科第2分野に属する多くの分野に存在する.記憶のモデルでおこなった,数理的メタファーと観測データをデータ駆動型のアプローチで統一的に議論することで,これをデータ駆動科学という新しい学問体系の構築につなげることができるのではないかと考えた.
データ駆動科学の三つのレベル
我々は,スパースモデリング(SpM)がデータ駆動科学創成のための数理的なキーテクノロジーであると考えた.SpMとは,(1)高次元データの説明変数が次元数よりも少ない(スパース)と仮定し,(2)説明変数の個数が小さくなることと,データへの適合とを同時に要請することにより,(3)人手に頼らない自動的な説明変数の選択を可能にする枠組みである.しかしながら,ここではSpMなどの数理的枠組みと実験データだけでは,データの背後にある科学的知見を抽出することが難しいことを強調したい.見かけ上派手でスマートに見える,数理的手法や情報科学的手法を,何も考えずに,気軽にデータ解析に持ちこめば良いという話ではない.もしかすると,それでは事がうまく運ばないと感じられている読者も多いかもしれない.
これをさきほどの連想記憶モデルを例に説明する.Sugaseらのデータに,主成分分析やクラスタリングを適用しようとする背景には,記憶やパターン認識のような課題では,神経系が図1のように挙動するのではないかという,神経科学や力学系の知見が必要である.その上でSpMなどのデータ解析手法を適用しなければ,データ解析の結果を適切に評価できない.そのためには,データの背後に,図1のような,対象の科学を記述する数理的なメタファーが必要なのである.その数理的なメタファーとして,現象やデータを第一原理的に定量的に説明する数理モデルが存在すれば,それを用いれば良いが,必ずしもそのような定量的な数理モデルが存在しない場合の方が圧倒的に多い.
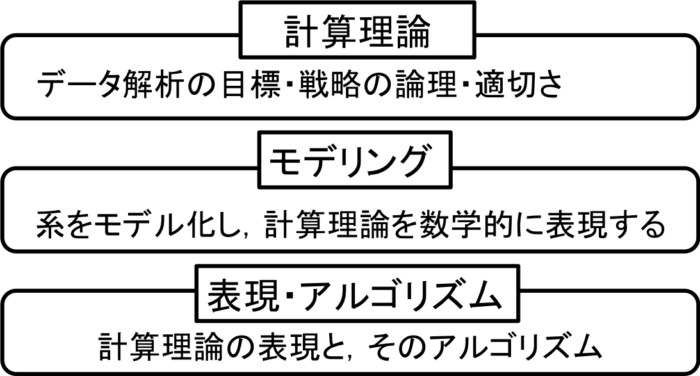
このように対象とデータの間を,様々な視点を持って,巧妙につなぐことは,多くの場合,個々の研究者の技量に任されていた.その技量には,実験家,理論家を問わずに,個々の研究者が対象とする系に,豊かな数理的メタファーを持つことが背景としてあるのではないかと,私は考えている.これを系統的な科学の枠組みに引き上げるためには,データ駆動科学の学理の原点が必要である.そこで我々は,理論神経科学者であり,視覚の計算理論でコンピュータービジョンにも大きな影響を与えたDavid Marrが提案したMarrの三つのレベルを参考にし,図2のデータ駆動科学の三つのレベルをデータ駆動科学の学理の原点として提案した.計算理論のレベルでは,データ解析の対象の科学と,データ獲得の原理を担う計測科学の知見が必要である.表現とアルゴリズムのレベルでは,データ解析手法の開発を機械学習などの情報科学が担う.中間のモデリングのレベルが,モデルを使った数理的な表現への変換を担当する.変換されるのは計算理論のレベルで議論されたデータ解析の目標や,データ解析のロジックである.ここで重要なことは,このモデリングのレベルでは,系をモデリングする際のモデルは,必ずしも系を定量的に記述するモデルである必要はないということである.つまり,連想記憶モデルのような数理的メタファーとしてのモデルでも十分であることもある.そのようなモデルの曖昧さについては,まずはモデルにある程度の自由度を与えておき,ベイズ的モデル選択やSpMを用いて,データを説明する適切な自由度のモデルを決定することができる.
まとめ
本稿では,数理的メタファーを実証的に検証する枠組みの模索から,SpMによるデータ駆動科学の創成にいたる経緯を紹介した.その過程で,定量的記述能力はないが,系の挙動の本質を抽象化したモデル,数理的メタファーが重要な概念であることを説明した.また,その数理的メタファーを実データにもとづく実証的な研究に埋め込む枠組みとして,データ駆動科学の三つのレベルを紹介した.
[1] J.J. Hopfield: Proc. Natl. Acad. Sci. U. S. A., Vol. 79(8), pp. 2554-2558 (1982).
[2] S.-I. Amari: Biol. Cybern., Vol. 26(3), pp. 175-185 (1977).
[3] K. Toya et al.: J. Phys. A. Math. Gen. , Vol. 33, pp. 2725-2738 (2000).
[4] N. Matsumoto et al.: J. Comput. Neurosci., Vol. 18, pp. 85-103 (2005).
[5] Y. Sugase et al.: Nature, Vol. 400, pp. 869-873 (1999).
[6] N. Matsumoto et al.: Cereb. Cortex, Vol. 15, pp. 1103-1112 (2005).